Introduction to Artificial Intelligence - Homework Assignment 04 (20pts.)¶
- NETIDs:
This assignment covers the following topics:
- Feed-Forward Neural Networks
- Gradient Descent and Backpropagation
- Convolutional Neural Networks
It will consist of 5 tasks (with an optional 6th bonus task):
| Task ID | Description | Points |
|---|---|---|
| 00 | Load Dataset | 0 |
| 01 | Feed-Forward Neural Network | |
| 01-1 | - Linear Layer | 1 |
| 01-2 | - ReLU Activation Function | 1 |
| 01-3 | - Feed-Forward Neural Network | 5 |
| 01-4 | - FFN Eval | 1 |
| 01-5 | - FFN Target Accuracy | 1 |
| 02 | Torch Feed-Foward Neural Network | |
| 02-1 | - Torch FFN Definition | 1 |
| 02-2 | - Torch FFN Training Function | 1 |
| 02-3 | - Torch FFN Evaluation | 1 |
| 02-4 | - FFN Short Answer Questions | 2 |
| 03 | Torch Convolutional Neural Network | |
| 03-1 | - Torch CNN Definition | 1 |
| 03-2 | - Torch CNN Training Function | 1 |
| 03-3 | - Torch CNN Evaluation | 2 |
| 03-4 | - CNN Short Answer Questions | 2 |
| 04 | Final OCR Evaluation | 0 |
| 05 | Bonus Task: Convolutional Neural Network | +3 |
| 05-1 | - Convolutional Layer | |
| 05-2 | - Max Pooling Layer | |
| 05-3 | - Flattening Layer | |
| 05-4 | - Convolutional Neural Network | |
| 05-5 | - CNN Eval |
Please complete all non-bonus sections. Some questions may require written answers, while others may involve coding. Be sure to run your code cells to verify your solutions.
Story Progression¶
Now that you have the segmented letters from the previous task, we need a way to actually convert the letters to text! You can't be bothered to just transcribe the images yourself, but you remember your professor droning on about something called MNIST and you think that these letters might be kind of similar to handwritten digits.
Unfortunately because your professor hates you, he's making you write a FFN using only tensors for the first part of this assignment. Use the dataset available from the github for training, testing, and validation on this assignment.
Task 00: Load Dataset¶
Task 00: Description (0 pts.)¶
Loading the EMNIST Subset Dataset¶
In class several times we've seen the MNIST dataset, the kidnapping letters are similar but they contain alphabet characters, so we need to use something slightly different to train our OCR models for this task. Luckily their exists an extended version of MNIST --- EMNIST that has not only the handwritten digits, but the handwritten alphabet as well. We can use a subset of this dataset to train our OCR models. Below I've added code to load in the dataset and convert it all to tensors for you.
Task 00: Code (0 pts.)¶
import os
import random
import math
import numpy as np
import matplotlib.pyplot as plt
import json, torch, torch.nn as nn, torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader, TensorDataset, random_split
from pathlib import Path
try:
import google.colab
REPO_URL = "https://github.com/nd-cse-30124-fa25/cse-30124-homeworks.git"
REPO_NAME = "cse-30124-homeworks"
HW_FOLDER = "homework04"
# Clone repo if not already present
if not os.path.exists(REPO_NAME):
!git clone {REPO_URL}
# cd into the homework folder
%cd {REPO_NAME}/{HW_FOLDER}
except ImportError:
pass
class DeviceDataLoader:
def __init__(self, dataloader, device):
self.dataloader = dataloader
self.device = device
def __iter__(self):
for xb, yb in self.dataloader:
yield xb.to(self.device), yb.to(self.device)
def __len__(self):
return len(self.dataloader)
def load_dataset(data_name, device='cpu', batch_size=128, val_fraction=0.1, seed=42):
DATA_FOLDER = f'{data_name}'
TRAIN_FILE = f"{DATA_FOLDER}/{data_name}_train.npz"
TEST_FILE = f"{DATA_FOLDER}/{data_name}_test.npz"
CLASSES_FILE = f"{DATA_FOLDER}/classes.json"
# Seeds
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
use_pin = (device.type == "cuda") # pin_memory mainly benefits CUDA
# ---- Load arrays: X: (N, 28, 28) uint8, y: (N,) int64 ----
train_npz = np.load(TRAIN_FILE)
X_train = train_npz["X"]
y_train = train_npz["y"]
test_npz = np.load(TEST_FILE)
X_test = test_npz["X"]
y_test = test_npz["y"]
with open(CLASSES_FILE, "r") as f:
classes = json.load(f)["classes"]
num_classes = len(classes)
print(f"Train: {X_train.shape}, Test: {X_test.shape}, Classes: {num_classes}")
# ---- Tensors for batch-first CNNs ----
# scale to [0,1], add channel dim -> (N, 1, 28, 28); labels stay indices (N,)
X_train_t = torch.from_numpy(X_train).to(torch.float32).div(255.0).unsqueeze(1)
y_train_t = torch.from_numpy(y_train).to(torch.long)
X_test_t = torch.from_numpy(X_test ).to(torch.float32).div(255.0).unsqueeze(1)
y_test_t = torch.from_numpy(y_test ).to(torch.long)
full_train_ds = TensorDataset(X_train_t, y_train_t)
test_ds = TensorDataset(X_test_t, y_test_t)
# ---- Train/Val split ----
n_train = len(full_train_ds)
n_val = math.ceil(n_train * val_fraction)
n_main = n_train - n_val
train_ds, val_ds = random_split(
full_train_ds, [n_main, n_val],
generator=torch.Generator().manual_seed(seed)
)
# ---- DataLoaders (batch-first) ----
train_loader = DataLoader(
train_ds, batch_size=batch_size, shuffle=True,
num_workers=0, persistent_workers=False, pin_memory=use_pin
)
val_loader = DataLoader(
val_ds, batch_size=batch_size, shuffle=False,
num_workers=0, persistent_workers=False, pin_memory=use_pin
)
test_loader = DataLoader(
test_ds, batch_size=batch_size, shuffle=False,
num_workers=0, persistent_workers=False, pin_memory=use_pin
)
train_loader = DeviceDataLoader(train_loader, device)
val_loader = DeviceDataLoader(val_loader, device)
test_loader = DeviceDataLoader(test_loader, device)
print(f"Train/Val/Test sizes: {len(train_ds)}/{len(val_ds)}/{len(test_ds)}")
return train_loader, val_loader, test_loader, num_classes, classes
Task 01: Feed-Forward Neural Network¶
Task 01-1: Description (0 pts.)¶
Linear Layer¶
The best way to fully understand neural networks is to implement one from scratch. To that end you'll need to write classes for each component of a neural network that you'll need to use in your model. After waiting until the day before it's due to start this homework and with much wailing and gnashing of teeth many of you will say “Why do we have to write the backward pass when frameworks in the real world, such as TensorFlow, compute them for you automatically?”. To this end you may be well served by perusing this blogpost by one of the most famous AI researchers, Andrej Karpathy, titled Yes you should understand backprop. It starts with the following paragraph:
When we offered CS231n (Deep Learning class) at Stanford, we intentionally designed the programming assignments to include explicit calculations involved in backpropagation on the lowest level. The students had to implement the forward and the backward pass of each layer in raw numpy.
If you fully understand this assignment, and the first part of Homework05, you will have an extremely strong understanding of the fundamentals of deep learning. These are hard assignments however, so don't get frustrated.
We're going to start with a "LinearLayer" or the layer that will perform the linear transformation between the input, weights, and biases. Each component of our model will have 3 functions:
forward(self, X)backward(self, dA)update(self, lr)
However not every component will make use of these 3, for example, a ReLU doesn't have weights so while we need the function stub to call as we iterate through our layers, the ReLU itself has no weights to update and ass such will just pass. In the code cell below, implement the 3 functions needed for the LinearLayer.
Task 01-1: Code (1 pt.)¶
class LinearLayer:
"""
Fully connected layer that applies an affine transform in batch-first format.
Attributes:
W (torch.Tensor): Weight matrix of shape (output_dim, input_dim).
b (torch.Tensor): Bias row vector of shape (1, output_dim).
device (torch.device): Device storing the parameters.
X (torch.Tensor): Cached batch input from the latest forward pass.
dW (torch.Tensor): Gradient of the loss with respect to `W`.
db (torch.Tensor): Gradient of the loss with respect to `b`.
"""
def __init__(self, input_dim, output_dim, device='cpu'):
"""
Initialize weights and biases with He normal initialization.
Args:
input_dim (int): Number of input features per example.
output_dim (int): Number of output features produced by the layer.
device (torch.device or str): Device on which to allocate the parameters.
"""
self.device = device
self.W = torch.randn(output_dim, input_dim, device=self.device) * math.sqrt(2.0 / input_dim)
self.b = torch.randn(1, output_dim, device=self.device) * math.sqrt(2.0 / input_dim)
def forward(self, X):
"""
Apply the affine transform to a batch and cache the input for backward().
Args:
X (torch.Tensor): Input batch of shape (batch_size, input_dim).
Returns:
torch.Tensor: Output batch of shape (batch_size, output_dim).
"""
# TODO: Store the input and calculate and return the output of the linear layer
def backward(self, dA):
"""
Backpropagate the gradient through the affine transform.
Args:
dA (torch.Tensor): Upstream gradient of shape (batch_size, output_dim).
Returns:
torch.Tensor: Gradient with respect to the input of shape (batch_size, input_dim).
Side Effects:
Populates `dW` and `db` for use during the subsequent update().
"""
# TODO: Calculate the gradient of the loss with respect to the weights and biases
# TODO: Return the gradient of the loss with respect to the input
def update(self, lr):
"""
Apply an in-place gradient descent step using the stored gradients.
Args:
lr (float): Learning rate for the parameter update.
Returns:
None
"""
# TODO: Update the weights and biases of the layer using the learning rate
class ReLU:
"""
Element-wise rectified linear activation.
"""
def forward(self, X):
"""
Apply ReLU activation and cache the input tensor.
Args:
X (torch.Tensor): Input tensor of any shape.
Returns:
torch.Tensor: Tensor with negatives zeroed out, same shape as `X`.
"""
# TODO: Store the input and calculate and return the output of the ReLU layer
def backward(self, dA):
"""
Propagate gradients through the ReLU non-linearity.
Args:
dA (torch.Tensor): Upstream gradient matching the shape of the forward output.
Returns:
torch.Tensor: Gradient with respect to the input, zeroed where the cached input was non-positive.
"""
# TODO: Calculate and return the gradient of the loss with respect to the input
def update(self, lr):
"""
Keep API parity with trainable layers; ReLU has no parameters to update.
Args:
lr (float): Unused learning rate argument.
Returns:
None
"""
# TODO: Update the weights and biases of the layer using the learning rate
Task 01-3: Description (0 pts.)¶
Numpy Feed-Forward Neural Network Model Class¶
The previous 2 classes: LinearLayer and ReLU are all we need to implement a very simple FFN. We can stack a combination of these together and add a training loop to it and we should be good to go!
Task 01-3: Code (5 pts.)¶
class NeuralNetwork:
"""
Feed-forward network assembled from the custom Linear, ReLU, and Softmax layers.
The model consumes flattened EMNIST images `(batch_size, 784)` and produces
probability distributions over 47 balanced EMNIST classes.
Attributes:
device (torch.device): Device used for parameters and computation.
layers (list): Ordered sequence of layers applied during forward().
"""
def __init__(self, device='cpu', seed=42):
"""
Build the fully connected architecture and seed the random generator.
Args:
device (torch.device or str): Device used for tensors and parameters.
seed (int): Random seed for deterministic weight initialization.
"""
self.device = device
torch.manual_seed(seed)
# TODO: Define better model architecture
L1 = LinearLayer(784, 47, device=self.device)
softmax = Softmax()
self.layers = [L1, softmax]
def forward(self, X, eval=False):
"""
Sequentially apply each layer in the network.
Args:
X (torch.Tensor): Batch of flattened images of shape (batch_size, 784).
eval (bool): If True, return the softmax of the output of the network.
Returns:
torch.Tensor: Logits or Probabilities of shape (batch_size, 47) depending on eval.
"""
# TODO: Calculate the output of the network
def softmax(self, X):
"""
Args:
X (torch.Tensor): Input data with shape (n_classes, m), where n_classes is the number of classes
and m is the number of examples.
Returns:
torch.Tensor: Softmax probabilities with shape (n_classes, m).
"""
# TODO: Calculate the softmax of the input
def cross_entropy(self, logits, Y):
"""
Compute the mean cross-entropy loss for one-hot encoded targets.
Args:
logits (torch.Tensor): Predicted logits of shape (batch_size, num_classes).
Y (torch.Tensor): One-hot encoded targets with the same shape.
Returns:
torch.Tensor: Scalar loss tensor averaged over the batch.
"""
# TODO: Calculate and return the cross-entropy loss
def get_accuracy(self, logits, Y):
"""
Calculate classification accuracy for one-hot encoded labels.
Args:
logits (torch.Tensor): Predicted logits of shape (batch_size, num_classes).
Y (torch.Tensor): One-hot encoded targets with the same shape.
Returns:
torch.Tensor: Scalar tensor containing the accuracy fraction.
"""
# TODO: Calculate and return the accuracy of the network
def backprop(self, logits, Y):
"""
Backpropagate the cross-entropy gradient through all layers.
Args:
logits (torch.Tensor): Predicted logits of shape (batch_size, num_classes).
Y (torch.Tensor): One-hot encoded targets with the same shape.
Side Effects:
Updates each layer's cached gradients in preparation for parameter updates.
"""
# TODO: Calculate the gradient of the loss with respect to the input
def data_shaper(self, loader, num_classes=47):
"""
Adapt DataLoader batches to the flattened representation expected by the network.
Args:
loader (Iterable): DataLoader yielding `(images, labels)` batches.
num_classes (int): Number of classes for one-hot encoding.
Yields:
tuple[torch.Tensor, torch.Tensor]: Flattened images `(batch_size, 784)` and
one-hot labels `(batch_size, num_classes)`.
"""
for xb, yb in loader:
X_batch = xb.flatten(start_dim=1) # Reshape to (784, m)
Y_batch = torch.eye(num_classes, dtype=torch.float32, device=self.device)[yb]
yield X_batch, Y_batch
def train(self, train_loader, val_loader, epochs=100, learning_rate=0.001, verbose=True):
"""
Train the network using mini-batch gradient descent on the provided loaders.
Args:
train_loader (DataLoader): Iterable that yields training batches.
val_loader (DataLoader): Iterable that yields validation batches.
epochs (int): Number of epochs to iterate over the training data.
learning_rate (float): Step size used during gradient descent updates.
verbose (bool): If True, log metrics every 10 epochs.
Returns:
dict: Contains `loss_history` and `accuracy_history` measured on the validation data.
"""
loss_history = []
accuracy_history = []
for i in range(epochs):
for X_batch, Y_batch in self.data_shaper(train_loader):
# Forward propagation
# TODO: Calculate the output of the network
# Backward propagation
# TODO: Calculate the gradients of the loss with respect to the input
# Update parameters
# TODO: Update the weights and biases of the layer using the learning rate
for X_batch, Y_batch in self.data_shaper(val_loader):
# Calculate metrics for the whole epoch on the validation set
Y_hat_full = self.forward(X_batch)
loss = self.cross_entropy(Y_hat_full, Y_batch)
accuracy = self.get_accuracy(Y_hat_full, Y_batch)
loss_history.append(loss)
accuracy_history.append(accuracy)
if verbose and i % 10 == 0:
print(f"Epoch {i+1}/{epochs}")
print(f"loss: {loss:.5f}")
print(f"accuracy: {accuracy:.5f}")
print("-" * 30)
return {'loss_history': loss_history, 'accuracy_history': accuracy_history}
Task 01-4: Description (0 pts.)¶
FFN Evaluation¶
The cell below will allow you to evaluate the performance of your FFN on the holdout set. Instead of giving hard values, which is basically impossible in deep learning, I'll be giving you a target output accuracy instead. Your goal is to reach 75% accuracy on the holdout set. You'll almost certainly have to test a number of different combinations of architectures and hyperparameters.
Task 01-4: Code (1 pt.)¶
def evaluate_on_holdout(test_loader, model):
"""
Evaluate a trained scratch model on a holdout DataLoader.
Args:
test_loader (DataLoader): Loader providing holdout `(images, labels)` batches.
model (NeuralNetwork): Trained network exposing `data_shaper`, `forward`, and `get_accuracy`.
Returns:
list: Accuracy values for each holdout batch.
"""
accuracy = []
# Get predictions
for X_batch, Y_batch in model.data_shaper(test_loader):
y_pred = model.forward(X_batch)
accuracy.append(model.get_accuracy(y_pred, Y_batch))
return accuracy
# Initialize and train model
device = torch.device('cuda' if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu")
train_loader, val_loader, test_loader, num_classes, classes = load_dataset('emnist_balanced_small', device=device)
model = NeuralNetwork(device=device)
history = model.train(train_loader, val_loader)
# Evaluate on holdout set
holdout_accuracy = evaluate_on_holdout(test_loader, model)
print(f"Holdout set accuracy: {torch.mean(torch.tensor(holdout_accuracy)):.5f}")
Task 01-5: Target Accuracy (1 pt.)¶
75%
Task 01-5: Reference Output (0 pts.)¶
Below is what my training run looked like when I passed the target 75% accuracy but it's possible yours may look slightly different, this is just intended to give you a general idea of what the numbers should look like.
Train: (9400, 28, 28), Test: (2350, 28, 28), Classes: 47
Train/Val/Test sizes: 8460/940/2350
Epoch 1/100
loss: 2.03566
accuracy: 0.40909
------------------------------
Epoch 11/100
loss: 0.88603
accuracy: 0.77273
------------------------------
Epoch 21/100
loss: 1.00684
accuracy: 0.68182
------------------------------
Epoch 31/100
loss: 0.95293
accuracy: 0.72727
------------------------------
Epoch 41/100
loss: 0.96932
accuracy: 0.77273
------------------------------
Epoch 51/100
loss: 1.10004
accuracy: 0.72727
------------------------------
Epoch 61/100
loss: 1.17194
accuracy: 0.70455
------------------------------
Epoch 71/100
loss: 1.11888
accuracy: 0.77273
------------------------------
Epoch 81/100
loss: 1.23379
accuracy: 0.72727
------------------------------
Epoch 91/100
loss: 1.29806
accuracy: 0.70455
------------------------------
Holdout set accuracy: 0.75602
Task 02: Description (0 pts.)¶
Task 02-1: Description (0 pts.)¶
Comparison to pytorch FFN implementation¶
Lets see how the FFN you wrote from scratch compares to a pytorch implementation! Make sure to use the same model architecture you used for your model! I'd encourage you to refer back to the notebook for the practicum to see a basic torch FFN model implementation.
Task 02-1: Code (1 pt.)¶
class FFN(nn.Module):
def __init__(self, num_classes=47):
super().__init__()
# TODO: Define model architecture
self.fc1 = nn.Linear(784, 47)
self._init_weights()
def _init_weights(self):
# He init for ReLU layers
for m in [self.fc1, self.fc2, self.fc3]:
nn.init.kaiming_normal_(m.weight, nonlinearity="relu")
nn.init.zeros_(m.bias)
# Last layer: slightly smaller std to avoid huge initial logits
nn.init.kaiming_normal_(self.fc4.weight, nonlinearity="linear")
nn.init.zeros_(self.fc4.bias)
def forward(self, x):
# TODO: Calculate and return the output of the network
def train(model, train_loader, val_loader, device, epochs=100, lr=1e-3):
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
for epoch in range(1, epochs + 1):
model.train()
running_loss, total, correct = 0.0, 0, 0
for xb, yb in train_loader:
# TODO: Run model training step
running_loss += loss.item() * xb.size(0)
preds = logits.argmax(dim=1)
correct += (preds == yb).sum().item()
total += xb.size(0)
train_loss = running_loss / total
train_acc = correct / total
val_loss, val_acc = evaluate(model, val_loader, device)
if epoch % 10 == 0:
print(f"Epoch {epoch:02d}/{epochs} | "
f"train_loss {train_loss:.4f} acc {train_acc:.4f} | "
f"val_loss {val_loss:.4f} acc {val_acc:.4f}")
return model
@torch.no_grad()
def evaluate(model, loader, device):
model.eval()
total, correct, running_loss = 0, 0, 0.0
for xb, yb in loader:
logits = model(xb)
loss = F.cross_entropy(logits, yb)
running_loss += loss.item() * xb.size(0)
preds = logits.argmax(dim=1)
correct += (preds == yb).sum().item()
total += xb.size(0)
avg_loss = running_loss / max(total, 1)
acc = correct / max(total, 1)
return avg_loss, acc
device = torch.device('cuda' if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu")
train_loader, val_loader, test_loader, num_classes, classes = load_dataset("emnist_balanced_small", device=device)
model = MLP(num_classes=num_classes)
model = train(model, train_loader, val_loader, device, epochs=100, lr=1e-3)
test_loss, test_acc = evaluate(model, test_loader, device)
print(f"TEST | loss {test_loss:.4f} acc {test_acc:.4f}")
Task 02-3: Reference Output (0 pts.)¶
Train: (9400, 28, 28), Test: (2350, 28, 28), Classes: 47
Train/Val/Test sizes: 8460/940/2350
Epoch 10/100 | train_loss 0.2911 acc 0.9035 | val_loss 0.8697 acc 0.7415
Epoch 20/100 | train_loss 0.0705 acc 0.9754 | val_loss 1.0084 acc 0.7628
Epoch 30/100 | train_loss 0.1041 acc 0.9649 | val_loss 1.3578 acc 0.7191
Epoch 40/100 | train_loss 0.0191 acc 0.9936 | val_loss 1.3311 acc 0.7713
Epoch 50/100 | train_loss 0.0168 acc 0.9944 | val_loss 1.4263 acc 0.7649
Epoch 60/100 | train_loss 0.1100 acc 0.9631 | val_loss 1.6886 acc 0.7138
Epoch 70/100 | train_loss 0.0068 acc 0.9983 | val_loss 1.6452 acc 0.7755
Epoch 80/100 | train_loss 0.0181 acc 0.9934 | val_loss 1.7808 acc 0.7532
Epoch 90/100 | train_loss 0.0043 acc 0.9992 | val_loss 1.7345 acc 0.7436
Epoch 100/100 | train_loss 0.0003 acc 1.0000 | val_loss 1.8476 acc 0.7543
TEST | loss 2.0233 acc 0.7472
Task 02-4: FFN Short Answer Questions (2 pts.)¶
What is the general intuition behind more layers generally improving our model?
- [ANSWER]
How do the number of epochs and learning rate interact?
- [ANSWER]
Story Progression¶
Wow, your model worked almost exactly as well as the one using the state-of-the-art library! That's pretty cool but while the FFN is okay, it's really not that well suited to image classification tasks such as this. Fighting through the hangover, you recall something about the news channel CNN? Implement a CNN (using pytorch) below and see if you can get a better result than the FFN.
Task 03: Convolutional Neural Network¶
Task 03-1: Description (0 pts.)¶
CNN Model Definition¶
Below we're going to implement a CNN in torch, CNNs are pretty tricky so if you don't want any bonus points we'll just stop with the torch version of it.
Task 03-1: Code (1 pt.)¶
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms
from PIL import Image
class CNN(nn.Module):
def __init__(self, num_classes=47):
super().__init__()
#TODO: Define the neural network architecture
def forward(self, x):
#TODO: Calculate the output of the network in the forward pass
def train_model(model, train_loader, val_loader, num_epochs=100 ,learning_rate=0.001):
"""
Train a PyTorch CNN and track train/validation metrics.
Args:
model (nn.Module): Convolutional network to optimize in-place.
train_loader (DataLoader): DataLoader supplying training batches.
val_loader (DataLoader): DataLoader supplying validation batches.
num_epochs (int): Number of epochs to train the model.
learning_rate (float): Learning rate for the Adam optimizer.
Returns:
tuple[list[float], list[float], list[float]]: Histories for training loss, training accuracy (percent),
and validation accuracy (percent).
"""
train_losses = []
train_accs = []
val_accs = []
criterion = F.nll_loss
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in train_loader:
# TODO: Train the model
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
epoch_loss = running_loss / len(train_loader)
train_acc = 100. * correct / total
model.eval()
correct = 0
total = 0
# TODO: Validate model on validation set
val_acc = 100. * correct / total
train_losses.append(epoch_loss)
train_accs.append(train_acc)
val_accs.append(val_acc)
if (epoch + 1) % 50 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {epoch_loss:.4f}, '
f'Train Acc: {train_acc:.2f}%, Val Acc: {val_acc:.2f}%')
return train_losses, train_accs, val_accs
def run_basic_cnn_experiment(train_loader, val_loader, test_loader):
# Initialize model and training components
device = torch.device('cuda' if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu")
model = CNN().to(device)
# Train model
train_losses, train_accs, val_accs = train_model(model, train_loader, val_loader, num_epochs=100)
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
# TODO: Evaluate on holdout set
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
holdout_acc = 100. * correct / total
print(f'Holdout Accuracy: {holdout_acc:.2f}%')
return model, (train_losses, train_accs, val_accs, holdout_acc)
# Run basic CNN experiment
print("Running Basic CNN Experiment...")
device = torch.device('cuda' if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu")
train_loader, val_loader, test_loader, num_classes, classes = load_dataset('emnist_balanced_small', device=device)
model, basic_metrics = run_basic_cnn_experiment(train_loader, val_loader, test_loader)
Task 03-3: Target Accuracy (1 pt.)¶
80% on Holdout Set
Task 03-3: Reference Output (0 pts.)¶
Instead of expected output, I'll give you the reference output from my run that managed to clear the 80% threshold but don't expect yours to necessarily be identical.
Running Basic CNN Experiment...
Train: (9400, 28, 28), Test: (2350, 28, 28), Classes: 47
Train/Val/Test sizes: 8460/940/2350
Epoch [50/100], Loss: 0.1541, Train Acc: 94.53%, Val Acc: 77.02%
Epoch [100/100], Loss: 0.0181, Train Acc: 99.52%, Val Acc: 80.43%
Holdout Accuracy: 80.77%
Task 03-4: CNN Short Answer Questions (2 pts.)¶
What makes the CNN a more natural fit for working with images?
- [ANSWER]
Why do we have both Convolutional Layers and Linear Layers in our network?
- [ANSWER]
Task 04: Inference on Segmented Letters¶
Task 04: Description (0 pts.)¶
Now that we have a model that we've trained to perform OCR, lets actually try and run it on the characters we extracted from the kidnapping letters on Homework03! We can then compare our predicted characters to the ground truth from the letters to see how well our combined segmentation + OCR actually did (not that well sadly)! Run the code below to perform the evaluation.
Task 04: Code (0 pts.)¶
from collections import defaultdict
class SegmentedLetterDataset(Dataset):
"""Dataset that loads segmented note letter PNGs for inference."""
def __init__(self, image_dir, transform=None):
self.image_dir = Path(image_dir)
if not self.image_dir.exists():
raise FileNotFoundError(f"Directory not found: {self.image_dir}")
self.image_paths = sorted(self.image_dir.glob('*.png'), key=self._sort_key)
if not self.image_paths:
raise ValueError(f"No PNG files found in {self.image_dir}")
self.transform = transform
@staticmethod
def _sort_key(path):
parts = path.stem.split('_')
note_idx = int(parts[1])
letter_idx = int(parts[3])
return note_idx, letter_idx
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
img_path = self.image_paths[idx]
image = Image.open(img_path).convert('L')
if self.transform:
image = self.transform(image)
return image, img_path.name
def load_segmented_letter_loader(image_dir='segmented_letter_images', batch_size=32):
"""Create a DataLoader over all segmented letter PNGs."""
transform = transforms.Compose([
transforms.Resize((28, 28)),
transforms.ToTensor(),
])
dataset = SegmentedLetterDataset(image_dir, transform=transform)
return DataLoader(dataset, batch_size=batch_size, shuffle=False)
seg_loader = load_segmented_letter_loader()
with open(Path('emnist_balanced_small') / 'classes.json', 'r') as f:
CLASSES = json.load(f)['classes']
if 'model' not in globals():
raise RuntimeError('Train the CNN model (Task 03) before running Task 04 inference.')
device = torch.device('cuda' if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu")
model = model.to(device)
model.eval()
pred_indices = []
file_names = []
with torch.no_grad():
for images, names in seg_loader:
images = images.to(device)
outputs = model(images)
pred_indices.extend(outputs.argmax(dim=1).cpu().tolist())
file_names.extend(names)
note_messages = defaultdict(str)
for name, idx in zip(file_names, pred_indices):
parts = name.replace('.png', '').split('_')
note_id = parts[1]
note_messages[note_id] += CLASSES[idx]
decoded_notes = {f'note_{note_id}': note_messages[note_id] for note_id in sorted(note_messages, key=int)}
ground_truth_output = [
'V YBIRQ ZHEQREVAT ZE GURVFRASYBLQ NG GUR RFGNGR GUR TNF JNF GUR CRESRPG ZHEQRE JRNCBA',
'VZ FHER VYY TRG NJNL JVGU VG NF JRYY UBCRSHYYL ABOBQL SVTHERF BHG GUR',
'PBZOVANGVBA BS GUR CNQYBPX CYNL BA YBPXRE 69 BA GUR FRPBAQ SYBBE BS PHFUVAT',
'BGUREJVFR V NZ VA ERNY GEBHOYR'
]
for note_id, text in decoded_notes.items():
print(f'{note_id}:')
print(f'\tExpected: {ground_truth_output[int(note_id[5])]}')
spaced_output = ''
space_offset = 0
error_count = 0
for idx, gt_char in enumerate(ground_truth_output[int(note_id[5])]):
if gt_char == ' ':
spaced_output += ' '
space_offset += 1
else:
try:
spaced_output += text[idx - space_offset]
if spaced_output[-1] != gt_char:
error_count += 1
except:
pass
print(f"\tPredicted: {spaced_output}")
print(f'\tAccuracy: {(len(text) - error_count) / len(text):.4f}\n')
Task 04-1: Reference Output¶
Here is my output for Task 04-1 but if you managed to train a better model than me you may beat my results!
note_0:
Expected: V YBIRQ ZHEQREVAT ZE GURVFRASYBLQ NG GUR RFGNGR GUR TNF JNF GUR CRESRPG ZHEQRE JRNCBA
Predicted: V 8BqBQ ZqB8REVA8 ZE BBRVPqASVBDQ nB BUP 3GGnGR BgB ZJG 3NG GBR CqIgRPG 88BBOP EJBWaB
Accuracy: 0.3889
note_1:
Expected: VZ FHER VYY TRG NJNL JVGU VG NF JRYY UBCRSHYYL ABOBQL SVTHERF BHG GUR
Predicted: Vq BqER JVq JBG NNNL 3VBU VB NP DRqV VBgRgHDbA B0BBDS VqqBBfB qGG Ua
Accuracy: 0.3091
note_2:
Expected: PBZOVANGVBA BS GUR CNQYBPX CYNL BA YBPXRE 69 BA GUR FRPBAQ SYBBE BS PHFUVAT
Predicted: PBZDVGnBVBB Bg BBa CNB8BPX gYNL qA XBPXPE Be Gn BBq PBPqAO 8SXBB BB SPqPBVA
Accuracy: 0.3968
note_3:
Expected: BGUREJVFR V NZ VA ERNY GEBHOYR
Predicted: BGB3E8VPq V JJ VA EBnB GBBqOYR
Accuracy: 0.5200
The results here are pretty inaccurate. One reason is that it's reliant on our cropping from Homework03 working well and it's reliant on the training data looking similar to the test data, which isn't exactly the case here. All things considered though, I think it does pretty well.
Story Progression¶
Unfortunately, despite having the text, you still can't read it. It appears to be encoded with some kind of cipher. If only there were seq2seq models that you maybe could use to decode it...
Task 05: Bonus Task¶
Task 05-1: Description¶
Convolutional Neural Network from Scratch¶
For 3 bonus points, you can implement a Convolutional Neural Network from scratch in a manner similar to which you did the FFN. We can reuse our LinearLayer and our Softmax and ReLUs but we're going to need three new components: a ConvolutionalLayer, a MaxPoolingLayer, and a FlatteningLayer (this flatteninglayer is a bit silly but it makes our compositions a little cleaner).
It's relatively easy to implement a CNN with a bunch of nested for loops but it then runs extremely slowly so we're going to implement it with a technique called im2col where instead of having a bunch of very small scale matrix multiplications (very slow) we're going to flatten the entire convolutional computation on the entire batch into a singular matrix multiplication (very fast).
Our input to our forward pass will be
X (torch.tensor): Input data with shape (N, C_in, H, W) where:
N: batch size
C_in: input channels
H: input height
W: input width
but the computation we want to compute will be on a flattened X with dimensions:
(batch_size * output_width * output_height, input_channels * kernel_size * kernel_size)
Reminder that broadly speaking, a convolution is similar to sliding a kernel around an image.
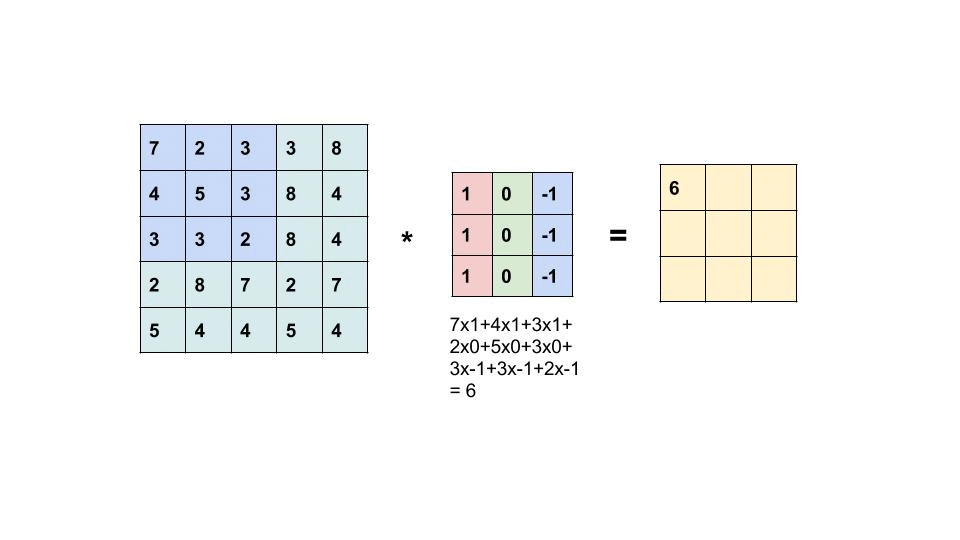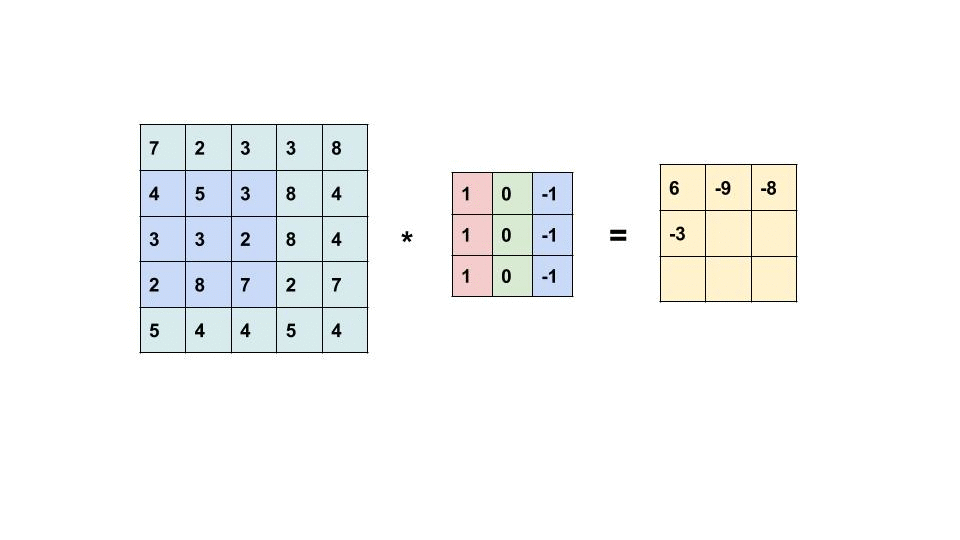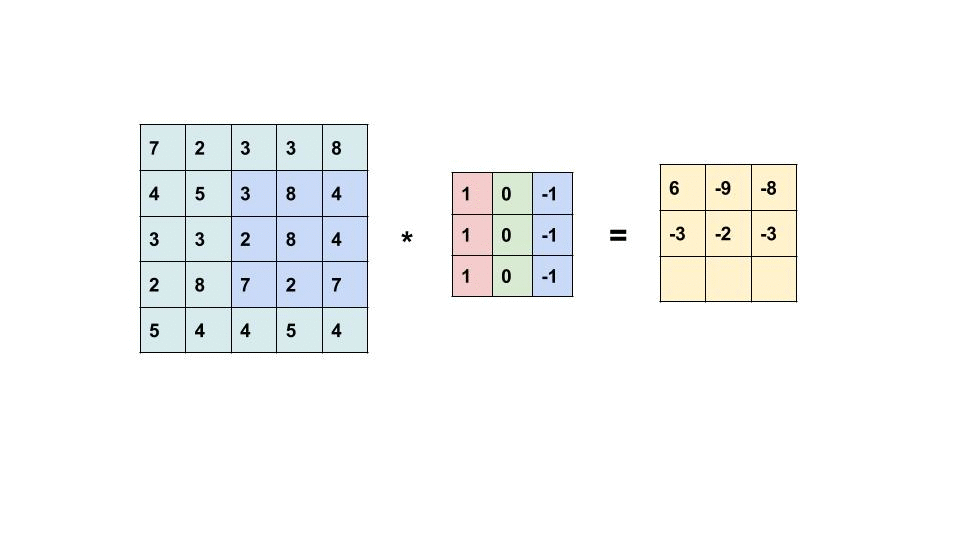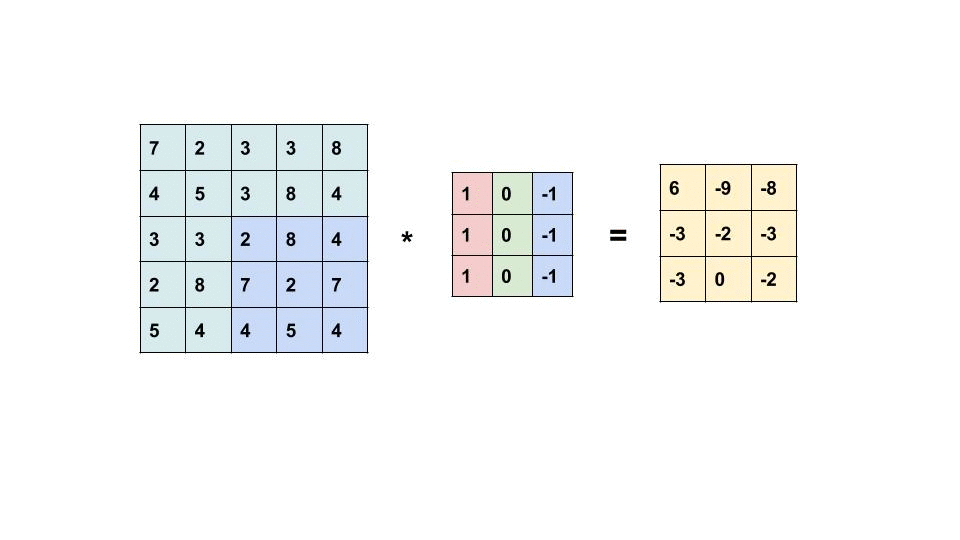
Task 05-1: Code¶
import torch
import math
class ConvolutionalLayer:
"""
2D convolution implemented with unfold (im2col) and matrix multiplication.
Attributes:
input_channels (int): Number of expected input channels.
output_channels (int): Number of convolutional filters.
kernel_size (int): Spatial extent of each square kernel.
device (torch.device): Device storing parameters and caches.
dtype (torch.dtype): Precision used for parameters and computations.
flattened_kernels_length (int): Elements per flattened kernel.
W (torch.Tensor): Weight matrix of shape (output_channels, flattened_kernels_length).
b (torch.Tensor): Bias vector of shape (output_channels,).
_X_shape (tuple): Cached input shape from the most recent forward pass.
_cols (torch.Tensor): Cached unfolded input used during backward().
"""
def __init__(self, in_channels, out_channels, kernel_size, device='cpu', dtype=torch.float32):
"""
Create learnable parameters and caches for the convolutional layer.
Args:
in_channels (int): Number of input channels.
out_channels (int): Number of filters produced by the layer.
kernel_size (int): Size of the (square) convolutional kernel.
device (torch.device or str): Device on which to allocate the parameters.
dtype (torch.dtype): Data type used for parameters and computations.
"""
self.input_channels = in_channels
self.output_channels = out_channels
self.kernel_size = kernel_size
self.device = torch.device(device)
self.dtype = dtype
self.flattened_kernels_length = self.input_channels * kernel_size * kernel_size
self.W = torch.randn(out_channels, self.flattened_kernels_length, device=self.device, dtype=self.dtype) * math.sqrt(2.0 / self.flattened_kernels_length)
self.b = torch.zeros(out_channels, device=self.device, dtype=self.dtype)
self._X_shape = None
self._cols = None
def forward(self, X):
"""
Apply the convolution to a batch of images.
Args:
X (torch.Tensor): Input tensor of shape (batch_size, C_in, H, W).
Returns:
torch.Tensor: Output tensor of shape (batch_size, C_out, H_out, W_out).
"""
batch_size, input_channels, input_height, input_width = X.shape
output_height = input_height - self.kernel_size + 1
output_width = input_width - self.kernel_size + 1
# TODO: Compute the im2col matrix
# TODO: Compute the convolution as a matrix multiplication + bias addition
# TODO: Reshape the output back to (N, C_out, H_out, W_out)
self._X_shape = X.shape
self._cols = cols
return Z
def backward(self, dA):
"""
Backpropagate gradients through the convolutional layer.
Args:
dA (torch.Tensor): Upstream gradient of shape (batch_size, C_out, H_out, W_out).
Returns:
torch.Tensor: Gradient with respect to the input of shape (batch_size, C_in, H, W).
Side Effects:
Stores gradients for `W` and `b` in `dW` and `db`.
"""
batch_size, input_channels, input_height, input_width = self._X_shape
output_height, output_width = dA.shape[2], dA.shape[3]
flattened_output_length = output_height * output_width
# TODO: Correctly shape dA and self._cols for gradient computations
# TODO: Compute gradients w.r.t. weights and biases
# TODO: Compute gradient w.r.t. input
# TODO: Reshape dcols back to the original input shape
return dX
def update(self, lr):
"""
Apply a gradient descent step to the convolutional parameters.
Args:
lr (float): Learning rate for the parameter update.
Returns:
None
"""
# TODO: Update the weights and biases of the layer using the learning rate

class MaxPoolingLayer:
"""
Max pooling layer that downsamples by taking the largest value in each non-overlapping window.
Attributes:
kernel_size (int): Edge length of the square pooling window.
_X_shape (tuple): Cached input shape from the forward pass.
_idx (torch.Tensor): Indices of the maxima within each pooling window.
"""
def __init__(self, kernel_size=2):
self.kernel_size = kernel_size
# caches for backward
self._X_shape = None
self._idx = None # argmax in the (kH*kW) window, shape (N, C, H_out, W_out)
def forward(self, X):
"""
Downsample the input by taking the maximum in each window.
Args:
X (torch.Tensor): Input tensor of shape (batch_size, C_in, H, W).
Returns:
torch.Tensor: Output tensor of shape (batch_size, C_in, H_out, W_out).
"""
batch_size, num_channels, input_height, input_width = X.shape
# require perfect tiling by the kernel
output_height, output_width = input_height // self.kernel_size, input_width // self.kernel_size
# TODO: Reshape X to get non-overlapping blocks
# TODO: Compute max and argmax in each window
# cache for backward
self._X_shape = (batch_size, num_channels, input_height, input_width)
self._idx = idx.contiguous()
return Y
def backward(self, dA):
"""
Route gradients to the inputs that achieved the pooled maxima.
Args:
dA (torch.Tensor): Upstream gradient of shape (batch_size, C_in, H_out, W_out).
Returns:
torch.Tensor: Gradient with respect to the input of shape (batch_size, C_in, H, W).
"""
batch_size, num_channels, input_height, input_width = self._X_shape
output_height, output_width = input_height // self.kernel_size, input_width // self.kernel_size
K = self.kernel_size * self.kernel_size
# TODO: Build one-hot mask in window dim (last) using cached argmax
# TODO: invert the reshape/permutation:
# (N,C,H_out,W_out,K) -> (N,C,H_out,kH,W_out,kW)
# TODO: merge the block dims back to H,W
return dX
def update(self, lr):
"""
Pooling has no parameters, so no update is required.
Args:
lr (float): Unused learning rate argument.
Returns:
None
"""
# TODO: Update the weights and biases of the layer using the learning rate
Task 05-3: Description¶
Flattening Layer from Scratch¶
The flattening layer isn't really a real thing, but between our Convolutional Layers and Linear Layers we need to flatten our feature vector and for the purpose of continuining to use a single loop, we'll write this flatten layer just to simplify the composition of the components of the model.
Task 05-3: Code¶
class FlattenLayer:
"""
Layer that reshapes convolutional feature maps into flat vectors.
Attributes:
input_shape (tuple): Cached shape needed to restore the tensor during backward().
"""
def __init__(self):
self.input_shape = None # to remember shape for backward
def forward(self, X):
"""
Flatten convolutional features while remembering the original shape.
Args:
X (torch.Tensor): Input tensor of shape (batch_size, C_in, H, W).
Returns:
torch.Tensor: Flattened tensor of shape (batch_size, C_in * H * W).
"""
self.input_shape = X.shape
# TODO: Flatten X to (N, C*H*W)
return X_flat
def backward(self, dY):
"""
Restore gradients to the original convolutional feature map shape.
Args:
dY (torch.Tensor): Upstream gradient of shape (batch_size, C_in * H * W).
Returns:
torch.Tensor: Gradient reshaped to (batch_size, C_in, H, W).
"""
N, C, H, W = self.input_shape
# TODO: Reshape dY back to the original input shape
return dX
def update(self, lr):
"""
No parameters to update; method kept for interface consistency.
Args:
lr (float): Unused learning rate argument.
Returns:
None
"""
# TODO: Update the weights and biases of the layer using the learning rate
Task 05-4: Description¶
Convolutional Neural Network from Scratch¶
Similar to our FFN model, we'll define a CNN Class that will contain all our components and let us train and run our model. You should just use the same model architecture you used for the torch CNN and many of the functions can be re-used from your FFN model.
Task 05-4: Code¶
class ConvolutionalNeuralNetwork:
"""
Convolutional network composed of custom convolution, pooling, and linear layers.
Designed for EMNIST images shaped `(batch_size, 1, 28, 28)` and outputs probabilities
across 47 character classes.
Attributes:
device (torch.device): Device used for parameters and computation.
layers (list): Ordered sequence of layers applied during forward().
"""
def __init__(self, device='cpu', seed=42):
"""
Instantiate the CNN architecture and seed parameter initialization.
Args:
device (torch.device or str): Device used for tensors and parameters.
seed (int): Random seed for deterministic weight initialization.
"""
self.device = device
torch.manual_seed(seed)
# TODO: Define better model architecture
C1 = ConvolutionalLayer(in_channels=1, out_channels=32, kernel_size=5, device=self.device)
P1 = MaxPoolingLayer()
R1 = ReLU()
F1 = FlattenLayer()
L1 = LinearLayer(1024, 128, device=self.device)
softmax = Softmax()
self.layers = [C1, P1, R1,
F1,
L1, softmax]
def forward(self, X):
"""
Pass a batch of images through all layers of the CNN.
Args:
X (torch.Tensor): Input batch of shape (batch_size, 1, 28, 28).
Returns:
torch.Tensor: Probabilities of shape (batch_size, 47).
"""
# TODO: Calculate the output of the network
return X
def cross_entropy(self, Y_hat, Y):
"""
Compute mean cross-entropy loss for softmax probabilities.
Args:
Y_hat (torch.Tensor): Predicted probabilities of shape (batch_size, num_classes).
Y (torch.Tensor): One-hot encoded targets with the same shape.
Returns:
torch.Tensor: Scalar loss tensor averaged over the batch.
"""
# TODO: Calculate the cross-entropy loss
def convert_prob_into_class(self, probs):
"""
Convert probability vectors into predicted class indices.
Args:
probs (torch.Tensor): Probabilities of shape (batch_size, num_classes).
Returns:
torch.Tensor: Predicted class indices of shape (batch_size,).
"""
# TODO: Convert the probabilities into a class
def get_accuracy(self, Y_hat, Y):
"""
Compute classification accuracy for one-hot encoded labels.
Args:
Y_hat (torch.Tensor): Predicted probabilities of shape (batch_size, num_classes).
Y (torch.Tensor): One-hot encoded targets with the same shape.
Returns:
torch.Tensor: Scalar tensor containing the accuracy fraction.
"""
# TODO: Calculate the accuracy of the network
return acc
def backprop(self, Y_hat, Y):
"""
Backpropagate cross-entropy gradients through all CNN layers.
Args:
Y_hat (torch.Tensor): Predicted probabilities of shape (batch_size, num_classes).
Y (torch.Tensor): One-hot encoded targets with the same shape.
Side Effects:
Updates each layer's cached gradients for parameter updates.
"""
# TODO: Calculate the gradient of the loss with respect to the input
def data_shaper(self, loader, num_classes=47):
"""
Prepare DataLoader batches for the CNN training loop.
Args:
loader (Iterable): DataLoader yielding `(images, labels)` batches.
num_classes (int): Number of classes for one-hot encoding.
Yields:
tuple[torch.Tensor, torch.Tensor]: Images `(batch_size, 1, 28, 28)` and one-hot
labels `(batch_size, num_classes)`.
"""
for xb, yb in loader:
Y_batch = torch.eye(num_classes, dtype=torch.float32, device=self.device)[yb]
yield xb, Y_batch
def train(self, train_loader, val_loader, epochs=100, learning_rate=0.001, verbose=True):
"""
Train the CNN with mini-batch gradient descent on the provided loaders.
Args:
train_loader (DataLoader): Iterable that yields training batches.
val_loader (DataLoader): Iterable that yields validation batches.
epochs (int): Number of epochs to iterate over the training data.
learning_rate (float): Step size used during gradient descent updates.
verbose (bool): If True, log metrics every 10 epochs.
Returns:
dict: Contains `loss_history` and `accuracy_history` measured on the validation data.
"""
loss_history = []
accuracy_history = []
for i in range(epochs):
for X_batch, Y_batch in self.data_shaper(train_loader):
# Forward propagation
# TODO: Calculate the output of the network
# Backward propagation
# TODO: Calculate the gradients of the loss with respect to the input
# Update parameters
# TODO: Update the weights and biases of the layer using the learning rate
for X_batch, Y_batch in self.data_shaper(val_loader):
# Calculate metrics for the whole epoch on the validation set
Y_hat_full = self.forward(X_batch)
loss = self.cross_entropy(Y_hat_full, Y_batch)
accuracy = self.get_accuracy(Y_hat_full, Y_batch)
loss_history.append(loss)
accuracy_history.append(accuracy)
if verbose and i % 10 == 0:
print(f"Epoch {i+1}/{epochs}")
print(f"loss: {loss:.5f}")
print(f"accuracy: {accuracy:.5f}")
print("-" * 30)
return {'loss_history': loss_history, 'accuracy_history': accuracy_history}
Task 05-5: Description¶
CNN from Scratch Training and Evaluation¶
Now that we have our CNN fully built, lets train it and see how it does on the test set! No target accuracy here, I just think it's neat that it works :) (though I was able to clear the target 80% with my hand-built one too)
Task 05-5: Code¶
def evaluate_on_holdout(test_loader, model):
"""
Evaluate the trained model on the holdout set
Args:
data_dict: Dictionary containing the dataset splits
model: Trained NumpyNeuralNetwork model
Returns:
float: Accuracy on holdout set
np.ndarray: Confusion matrix
"""
accuracy = []
# Get predictions
for X_batch, Y_batch in model.data_shaper(test_loader):
y_pred = model.forward(X_batch)
accuracy.append(model.get_accuracy(y_pred, Y_batch))
return accuracy
device = torch.device('cuda' if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu")
# Load dataset
train_loader, val_loader, test_loader, num_classes, classes = load_dataset('emnist_balanced_small', device=device)
# Initialize and train model
model = ConvolutionalNeuralNetwork(device=device)
history = model.train(train_loader, val_loader)
# Evaluate on holdout set
holdout_accuracy = evaluate_on_holdout(test_loader, model)
print(f"Holdout set accuracy: {torch.mean(torch.tensor(holdout_accuracy)):.5f}")
Task 05-5: Reference Output¶
Train: (9400, 28, 28), Test: (2350, 28, 28), Classes: 47
Train/Val/Test sizes: 8460/940/2350
Epoch 1/100
loss: 1.57598
accuracy: 0.56818
------------------------------
Epoch 11/100
loss: 0.70333
accuracy: 0.77273
------------------------------
Epoch 21/100
loss: 0.79560
accuracy: 0.81818
------------------------------
Epoch 31/100
loss: 0.92910
accuracy: 0.84091
------------------------------
Epoch 41/100
loss: 1.12943
accuracy: 0.81818
------------------------------
Epoch 51/100
loss: 1.19908
accuracy: 0.86364
------------------------------
Epoch 61/100
loss: 1.24729
accuracy: 0.84091
------------------------------
Epoch 71/100
loss: 1.26052
accuracy: 0.86364
------------------------------
Epoch 81/100
loss: 1.40077
accuracy: 0.84091
------------------------------
Epoch 91/100
loss: 1.43567
accuracy: 0.84091
------------------------------
Holdout set accuracy: 0.80322